
Algorithme
Renseignements généraux
Les articles de cette sélection écoles ont été organisés par sujet du programme d'études grâce aux bénévoles d'enfants SOS. Voulez-vous savoir sur le parrainage? Voir www.sponsorachild.org.uk
En mathématiques , informatique, la linguistique et des disciplines connexes, un algorithme est un type de méthode dans laquelle une liste définitive d'instructions bien définies pour remplir une tâche, quand donné un état initial, sera traité par une série bien définie d'états successifs, éventuellement terminant dans un état final. La transition d'un état à l'autre ne est pas nécessairement déterministe; certains algorithmes, appelés algorithmes probabilistes, intègrent aléatoire.
Le concept d'un algorithme à l'origine un moyen de procédures pour résoudre des problèmes mathématiques tels que trouver le bon enregistrement diviseur de deux nombres ou la multiplication de deux nombres; ces algorithmes étaient utilisés par les Babyloniens dès 1600 BC.
Une formalisation partielle du concept a commencé avec des tentatives pour résoudre le Entscheidungsproblem (le «problème de décision") que David Hilbert posé en 1928. formalisations ultérieures étaient conçues comme des tentatives de définir " calculabilité effective "(Kleene 1943: 274) ou« méthode »(Rosser 1939: 225); ces formalisations inclus l'Gödel-Herbrand-Kleene fonctions récursives de 1930, 1934 et 1935, Eglise Alonzo lambda-calcul de 1936, "Formulation I" d'Emil Poster de 1936, et Alan Turing s ' Les machines de Turing de 1936-7 et 1939.
Étymologie
Al-Khwarizmi , Persique astronome et mathématicien , a écrit un traité en arabe en 825 après JC, sur le calcul des chiffres hindous. (Voir algorism). Il a été traduit en latin au 12e siècle comme Algoritmi de numero Indorum (al-Daffa 1977), dont le titre était susceptible entend "[Réserver par] Algoritmus sur les numéros des Indiens", où "Algoritmi" était la restitution du traducteur du nom de l'auteur dans le cas génitif; mais les gens incompréhension le titre Algoritmi traités comme un pluriel latine et ce qui a conduit au mot "algorithme" (de Algorismus latine) à venir pour signifier "méthode de calcul". Le "e" intrusive est probablement dû à un faux ami avec les grecs αριθμος (arithmos) signifie "nombre".
Pourquoi algorithmes sont nécessaires: une définition informelle
Aucune définition formelle généralement accepté de «algorithme» existe encore. Nous pouvons, cependant, tirer des indices sur les enjeux et un sens informel du mot de la citation suivante de Boolos & Jeffrey (1974, 1999) (gras ajouté):
Aucun être humain ne peut écrire assez vite ou assez longtemps ou assez petit pour lister tous les membres d'un ensemble enumerably infinie en écrivant leurs noms, un après l'autre, dans une notation. Mais les humains peuvent faire quelque chose d'aussi utile, dans le cas de certains ensembles infinis enumerably: Ils peuvent donner des instructions explicites pour déterminer la nième membre de l'ensemble, pour arbitraire finie n. Ces instructions doivent être donnés de manière très explicite, sous une forme dans laquelle ils pourraient être suivies par une machine de calcul, ou par un humain qui est capable de ne effectuer que des opérations très élémentaires sur les symboles (Boolos & Jeffrey 1974, 1999, p. 19 )
Les mots "enumerably infinie" signifient "en utilisant dénombrable entiers se étendant peut-être à l'infini". Ainsi Boolos et Jeffrey disent qu'un algorithme implique des instructions pour un processus qui "crée" entiers de sortie à partir d'une "entrée" entier arbitraire ou entiers qui, en théorie, peut être choisi parmi 0 à l'infini. Ainsi nous pourrions nous attendre un algorithme pour être une équation algébrique tels que y = m + n - deux «variables d'entrée" arbitraires m et n qui produisent une sortie y. Comme on le voit dans caractérisations de l'algorithme - le mot algorithme implique beaucoup plus que cela, quelque chose de l'ordre de (pour notre exemple de plus):
- Des instructions précises (en langue comprise par "l'ordinateur") pour une "efficace, bonne rapide," processus qui spécifie les "mouvements" de "l'ordinateur" (machine ou humain, équipé avec les informations contenues interne et les capacités nécessaires) pour trouver, décoder, puis grignoter arbitraires entiers d'entrée / symboles m et n, symboles + et = ... et (de manière fiable, correctement, «efficacement») de produire, dans un «raisonnable» le temps , sortie entier y en un lieu déterminé et dans un format spécifié.
Le concept d'algorithme est également utilisé pour définir la notion de décidabilité (logique). Cette notion est centrale pour expliquer comment systèmes formels naissent à partir d'un petit ensemble de axiomes et les règles. Dans la logique , le temps que nécessite un algorithme pour compléter ne peut pas être mesurée, car il ne est apparemment pas liée avec notre dimension physique coutumier. De telles incertitudes, qui caractérisent les travaux en cours, les tiges de l'indisponibilité d'une définition de l'algorithme qui convient à la fois concrète (en quelque sorte) et l'utilisation abstraite du terme.
- Pour une présentation détaillée des différents points de vue autour de la définition de "algorithme" voir caractérisations algorithme. Pour des exemples d'algorithmes simples d'addition spécifiées de la manière décrite dans l'détaillée caractérisations algorithme, consultez Exemples de algorithme.
Formalisation des algorithmes
Algorithmes sont essentiels à la façon dont les ordinateurs de traiter l'information, car un programme d'ordinateur est essentiellement un algorithme qui indique à l'ordinateur quelles mesures spécifiques à effectuer (dans quel ordre spécifique) afin d'effectuer une tâche précise, comme le calcul de chèques de paie ou l'impression étudiants des employés les bulletins. Ainsi, un algorithme peut être considéré comme ne importe quelle séquence d'opérations qui peuvent être effectuées par un Turing-complet système. Les auteurs qui affirment cette thèse comprennent Savage (1987) et Gurevich (2000):
... L'argument informel de Turing en faveur de sa thèse justifie une thèse forte: chaque algorithme peut être simulé par une machine de Turing (Gurevich 2000: 1) ... selon Savage [1987], un algorithme est un processus de calcul défini par une machine de Turing. (Gurevich 2000: 3)
Typiquement, quand un algorithme est associé au traitement d'informations, les données sont lues à partir d'une source ou d'un dispositif d'entrée, écrites dans un évier ou un dispositif de sortie, et / ou stockées pour un traitement ultérieur. Les données stockées sont considérés comme faisant partie de l'état interne de l'entité effectuant l'algorithme. Dans la pratique, l'état est stocké dans un structure de données, mais un algorithme nécessite les données internes seulement pour les jeux de fonctionnement spécifiques appelés types de données abstraits.
Pour tout ce processus de calcul, l'algorithme doit être rigoureusement défini: spécifié dans la façon dont elle se applique en toutes circonstances possibles qui pourraient survenir. Ce est, toutes les mesures conditionnelles doivent être systématiquement traitées au cas par cas; les critères pour chaque cas doit être clair (et calculable).
Parce que un algorithme est une liste précise des étapes précises, l'ordre de calcul sera presque toujours critique pour le fonctionnement de l'algorithme. Les instructions sont généralement supposés être énumérés explicitement, et sont décrites comme de départ "par le haut" et aller "vers le bas", une idée qui est décrit plus formellement par flux de contrôle.
Jusqu'à présent, cette discussion de la formalisation d'un algorithme a assumé les locaux de la programmation impérative. Ce est la conception la plus courante, et il tente de décrire une tâche dans discrets, des moyens «mécaniques». Unique à cette conception d'algorithmes formalisés est le opération d'affectation, le réglage de la valeur d'une variable. Elle découle de l'intuition de " mémoire "comme un bloc-notes. Il est un exemple ci-dessous d'une telle cession.
Pour certaines des conceptions différentes de ce qui constitue une mer de l'algorithme programmation fonctionnelle et programmation logique.
Résiliation
Certains auteurs limitent la définition de l'algorithme à des procédures qui terminent finalement. Dans une telle catégorie Kleene place la "méthode de procédure de décision ou de la décision ou de l'algorithme pour la question" (Kleene 1952: 136). D'autres, dont Kleene, incluent des procédures qui pourrait fonctionner pour toujours sans se arrêter; une telle procédure a été appelé une "méthode de calcul" (Knuth 1997: 5) ou «procédure de calcul ou d'un algorithme" (Kleene 1952: 137); toutefois, Kleene note qu'une telle méthode doit finalement présenter "un objet" (Kleene 1952: 137).
Minsky fait l'observation pertinente, en ce qui concerne déterminer si un algorithme finira fin (d'un état de départ particulier):
Mais si la longueur de la procédure ne est pas connue à l'avance, puis 'essayer' il ne peut pas être décisif, parce que si le processus ne va éternellement - puis à aucun moment nous ne jamais être sûr de la réponse (Minsky 1967: 105) .
Comme il arrive, aucune autre méthode ne peut faire mieux, comme l'a montré par Alan Turing avec son célèbre résultat sur l'indécidabilité de la soi-disant problème de l'arrêt. Il ne existe aucune procédure algorithmique pour déterminer des algorithmes arbitraires ou non ils se terminent par les Etats de départ donné. L'analyse d'algorithmes pour leur probabilité de résiliation est appelé analyse de résiliation.
Voir les exemples de (im -) soustraction "bon" au fonction partielle pour plus sur ce qui peut arriver quand un algorithme échoue pour certains de ses numéros d'entrée - par exemple, (i) non-terminaison, (ii) la production de "junk" (sortie dans le mauvais format à être considéré comme un numéro) ou pas Numéro (s) du tout (arrêt termine le calcul sans sortie), (iii) un mauvais numéro (s), ou (iv) une combinaison de ces. Kleene proposé que la production de "junk" ou défaut de produire un certain nombre est résolu en ayant l'algorithme détecter ces cas et de produire par exemple, un message d'erreur (il a suggéré «0»), ou de préférence, forcer l'algorithme dans une boucle sans fin ( Kleene 1952: 322). Davis fait cela à son algorithme de soustraction - il fixe son algorithme dans un deuxième exemple de telle sorte que ce est une bonne soustraction (Davis 1958: 12-15). Avec les résultats logiques «vrai» et «faux» Kleene propose également l'utilisation d'un troisième symbole logique "u" - indécis (Kleene 1952: 326) - donc un algorithme sera toujours produire quelque chose face à une «proposition». Le problème des mauvaises réponses doit être résolu avec une "preuve" indépendante de l'algorithme par exemple, en utilisant l'induction:
Nous exigeons normalement preuves auxiliaire pour ce (que l'algorithme définit correctement une mu fonction récursive), par exemple, sous la forme d'une preuve inductive que, pour chaque valeur de l'argument, le calcul se termine avec une valeur unique (Minsky 1967: 186).
Exprimant algorithmes
Les algorithmes peuvent être exprimés dans de nombreux types de notation, y compris langues naturelles, pseudo, organigrammes, et les langages de programmation . Expressions en langage naturel d'algorithmes ont tendance à être verbeux et ambiguë, et sont rarement utilisés pour les algorithmes complexes ou techniques. Pseudocode et organigrammes sont des moyens structurés pour exprimer des algorithmes qui permettent d'éviter la plupart des ambiguïtés communs dans les états du langage naturel, tout en restant indépendant d'un langage de mise en œuvre particulière. Les langages de programmation sont principalement destinés à exprimer des algorithmes sous une forme qui peut être exécuté par un ordinateur , mais sont souvent utilisés comme un moyen de définir ou algorithmes de documents.
Il ya une grande variété de représentations possible et on peut exprimer une donnée Turing programme de la machine comme une séquence de tables de machine (voir plus à machine à états finis et transition d'état de table), comme des organigrammes (voir plus à diagramme d'état), ou comme une forme de rudimentaires code machine ou code assembleur appelé "ensembles de quadruples" (voir plus au Machine de Turing).
Parfois, il est utile dans la description d'un algorithme pour compléter petits "organigrammes" (diagrammes état) en langage naturel et / ou expressions arithmétiques écrites à l'intérieur " diagrammes "Pour résumer ce que les« organigrammes »accomplissent.
Représentations algorithmes sont généralement classés en trois niveaux acceptés de description de machine de Turing (Sipser 2006: 157):
- Description 1 de haut niveau:
- "... La prose pour décrire un algorithme, en ignorant les détails de mise en œuvre. A ce niveau, nous ne avons pas besoin de mentionner comment la machine gère sa cassette ou la tête"
- Description 2 de mise en œuvre:
- "... La prose utilisée pour définir la façon dont la machine de Turing utilise sa tête et la façon dont il stocke les données sur sa bande. A ce niveau, nous ne donnons pas de détails des Etats ou de la fonction de transition"
- 3 Description formelle:
- Plus détaillé, "plus bas niveau", donne "la table d'état" de la machine de Turing.
Exécution
La plupart des algorithmes sont destinés à être mis en oeuvre en tant que programmes informatiques. Cependant, les algorithmes sont également mis en œuvre par d'autres moyens, par exemple dans un biologique réseau de neurones (par exemple, la cerveau humain exécution arithmétique ou un insecte à la recherche de nourriture), dans une circuit électrique, ou dans un dispositif mécanique.
Exemple
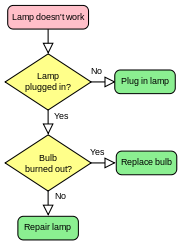
Un des algorithmes les plus simples est de trouver le plus grand nombre dans une liste (non triés) de nombres. La solution nécessairement faut examiner à chaque numéro de la liste, mais seulement une fois à chaque. De là découle un algorithme simple, qui peut être indiqué dans une description de haut niveau English prose, que:
Description de haut niveau:
- Supposons que le premier élément est le plus grand.
- Regardez chacun des éléments restants de la liste et se il est plus grand que le plus gros poste jusqu'à présent, faire une note.
- Le dernier élément noté est le plus grand dans la liste lorsque le processus est terminé.
(Quasi) description formelle: Écrit en prose, mais beaucoup plus proche du langage de haut niveau d'un programme informatique, ce qui suit est le codage plus formelle de l'algorithme pseudo ou Code pidgin:
Algorithme LargestNumber
Entrée: Une liste non vide de chiffres L.
Sortie: Le plus grand nombre dans la liste L.
Le plus grand L ← 0
pour chaque élément de la liste L ≥1, faire
si l'article> plus grand, puis
Le plus grand ← l'élément
revenir plus grand
- "←" est un raccourci pour "devient". Par exemple, «le plus grand élément de ←" signifie que la valeur des plus grands changements à la valeur de l'élément.
- «Retour» termine l'algorithme et émet la valeur qui suit.
Pour un exemple plus complexe d'un algorithme, consultez L'algorithme d'Euclide pour le plus grand commun diviseur , un des premiers algorithmes connus.
Algorithme d'analyse
Comme il arrive, il est important de savoir combien d'une ressource particulière (comme le temps ou le stockage) est nécessaire pour un algorithme donné. Des méthodes ont été développées pour la analyse des algorithmes pour obtenir ces réponses quantitatives; par exemple, l'algorithme ci-dessus a une exigence de temps en O (n), en utilisant la notation O grande avec n que la longueur de la liste. En tout temps l'algorithme ne doit se rappeler deux valeurs: le plus grand nombre trouvé jusqu'ici, et sa position actuelle dans la liste d'entrée. Par conséquent, il est dit d'avoir un encombrement de O (1), si l'espace nécessaire pour stocker les numéros d'entrée ne est pas compté, ou O (log n) si elle est comptée.
Différents algorithmes peuvent remplir la même tâche avec un ensemble différent d'instructions en moins ou de plus de temps, l'espace, ou d'effort que d'autres. Par exemple, compte tenu de deux recettes différentes pour faire la salade de pommes de terre, on peut avoir peler la pomme de terre avant de faire bouillir la pomme de terre tandis que l'autre présente les étapes dans l'ordre inverse, mais ils ont tous deux appel à ces mesures pour être répétée pour toutes les pommes de terre et fin lorsque le salade de pomme de terre est prêt à être mangé.
Le l'analyse et l'étude des algorithmes est une discipline de l'informatique , et est souvent pratiquée abstraitement, sans l'utilisation d'un spécifique langage de programmation ou de mise en œuvre. En ce sens, l'analyse de l'algorithme ressemble à d'autres disciplines mathématiques en ce qu'elle met l'accent sur les propriétés sous-jacentes de l'algorithme et non sur les détails de toute mise en œuvre particulière. Habituellement pseudo-code est utilisé pour l'analyse comme ce est la représentation la plus simple et le plus général.
Classes
Il existe différentes façons de classer les algorithmes, chacun avec ses propres mérites.
Classification par la mise en œuvre
Une façon de classer les algorithmes est par des moyens de mise en œuvre.
- Récursivité ou itération: A algorithme récursif est celui qui invoque (fait référence à) jusqu'à ce que lui-même un certains matchs de condition, qui est une méthode commune à programmation fonctionnelle. Algorithmes itératifs utilisent constructions répétitives comme les boucles et les structures de données supplémentaires comme parfois piles pour résoudre les problèmes donnés. Certains problèmes sont naturellement adaptés pour une mise en œuvre ou de l'autre. Par exemple, tours de Hanoi est bien compris dans la mise en œuvre récursive. Chaque Version récursive a un équivalent (mais peut-être plus ou moins complexe) version itérative, et vice versa.
- Logique: Un algorithme peut être considérée comme contrôlée déduction logique. Cette notion peut être exprimée comme suit: Algorithme = + logique de contrôle (Kowalski 1979). Le composant logique exprime les axiomes qui peuvent être utilisés dans le calcul et le composant de commande détermine la manière dont la déduction est appliquée aux axiomes. Ce est la base de la paradigme de programmation logique. Dans les langages de programmation de la logique pure du composant de commande est fixe et algorithmes sont spécifiés en fournissant uniquement le composant logique. L'intérêt de cette approche est l'élégant sémantique: un changement dans les axiomes a un changement bien défini dans l'algorithme.
- Série ou parallèle ou distribué: Algorithmes sont habituellement discutés avec l'hypothèse que les ordinateurs exécutent une instruction d'un algorithme à la fois. Ces ordinateurs sont parfois appelés ordinateurs série. Un algorithme conçu pour un tel environnement est appelé un algorithme en série, par opposition à algorithmes parallèles ou algorithmes distribués. Algorithmes parallèles profitent des architectures informatiques où plusieurs processeurs peuvent travailler sur un problème en même temps, alors que les algorithmes distribués utilisent plusieurs machines connectées avec un réseau. Algorithmes parallèles ou distribués divisent le problème en sous plus symétriques ou asymétriques et de recueillir les résultats de retour ensemble. La consommation de ressources dans ces algorithmes ne sont pas seulement des cycles de processeur de chaque processeur, mais aussi le coût de communication entre les processeurs. Algorithmes de tri peuvent être parallélisés efficacement, mais leurs frais généraux de communication est cher. Algorithmes itératifs sont généralement parallélisables. Certains problèmes ne ont pas algorithmes parallèles, et sont appelés intrinsèquement problèmes série.
- Déterministe ou non-déterministe: Algorithmes déterministes de résoudre le problème à la décision exacte à chaque étape de l'algorithme alors algorithme non déterministe via résoudre les problèmes typiques deviner bien que des suppositions sont faites plus précise par l'utilisation de heuristiques.
- Exacte ou approximative: Alors que de nombreux algorithmes atteignent une solution exacte, algorithmes d'approximation cherchent une approximation qui est proche de la vraie solution. Rapprochement peut utiliser soit un déterministe ou une stratégie aléatoire. Ces algorithmes ont une valeur pratique pour de nombreux problèmes difficiles.
Classement par paradigme de conception
Une autre façon de classer les algorithmes est par leur méthodologie de conception ou d'un paradigme. Il existe un certain nombre de paradigmes, chacune différente de l'autre. En outre, chacune de ces catégories comprendra beaucoup de différents types d'algorithmes. Des paradigmes couramment trouvés sont les suivants:
- Diviser et conquérir. Un diviser et conquérir algorithme réduit à plusieurs reprises une instance d'un problème à un ou plusieurs petits instances du même problème (généralement récursive), jusqu'à ce que les cas sont assez petit pour résoudre facilement. Un exemple de diviser pour régner est fusionner tri. Tri peut être fait sur chaque segment de données après diviser les données en segments et de tri des données entières peuvent être obtenus en phase de conquête en les fusionnant. Une variante plus simple de diviser pour régner est appelé diminution et conquérir algorithme, qui résout un sous-problème identiques et utilise la solution de ce sous-problème à résoudre le plus grand problème. Diviser pour régner divise le problème en plusieurs sous-problèmes et ainsi de conquérir étape sera plus complexe que la diminution et conquérir algorithmes. Un exemple de diminution régner algorithme est Dichotomie.
- La programmation dynamique. Quand un problème montre sous-structure optimale, ce qui signifie la solution optimale à un problème peut être construit à partir de solutions optimales pour sous-problèmes, et sous-problèmes qui se chevauchent, ce qui signifie les mêmes sous-problèmes sont utilisées pour résoudre de nombreux cas de problèmes différents, une approche plus rapide appelé programmation dynamique évite les solutions de recalculer qui ont déjà été calculées. Par exemple, le chemin le plus court pour un objectif d'un sommet en un pondéré graphique peut être trouvée en utilisant le chemin le plus court à l'objectif de tous les sommets adjacents. La programmation dynamique et memoization aller ensemble. La principale différence entre la programmation dynamique et diviser pour régner, ce est que sous-problèmes sont plus ou moins indépendante sur diviser pour régner, alors sous-problèmes se chevauchent dans la programmation dynamique. La différence entre la programmation dynamique et la récursivité directe est mise en cache ou memoization d'appels récursifs. Lorsque sous-problèmes sont indépendants et il n'y a pas de répétition, memoization ne aide pas; donc programmation dynamique ne est pas une solution à tous les problèmes complexes. En utilisant memoization ou le maintien d'un table des sous-problèmes déjà résolu, programmation dynamique réduit la nature exponentielle de nombreux problèmes à la complexité polynomiale.
- La méthode gourmande. Un algorithme glouton est similaire à un algorithme de programmation dynamique, mais la différence est que les solutions aux sous-problèmes ne ont pas à être connu à chaque étape; au lieu d'un choix "gourmande" peut être faite de ce qui semble le mieux pour le moment. La méthode gourmande étend la solution avec la meilleure décision possible (pas toutes les décisions possibles) à un stade algorithmique basée sur le courant optimum local et la meilleure décision (pas toutes les décisions possibles) fait dans l'étape précédente. Il ne est pas exhaustive, et ne donne pas de réponse précise à de nombreux problèmes. Mais quand ça marche, ce sera la méthode la plus rapide. L'algorithme glouton plus populaire est de trouver l'arbre couvrant minimal donné par Kruskal.
- La programmation linéaire. Lorsque la résolution d'un problème à l'aide programmation linéaire, spécifique inégalités impliquant les entrées se trouvent, puis une tentative est faite pour maximiser (ou minimiser) une fonction linéaire des entrées. De nombreux problèmes (par exemple, la débit maximal pour dirigé graphiques) peut être indiqué d'une manière de programmation linéaire, puis être résolu par un algorithme «générique» comme le algorithme simplex. Une variante plus complexe de la programmation linéaire est appelé programmation en nombres entiers, où l'espace de solution est limitée aux nombres entiers .
- Réduction. Cette technique consiste à résoudre un problème difficile en le transformant en un problème mieux connu pour laquelle nous avons (nous l'espérons) algorithmes asymptotiquement optimale. Le but est de trouver un algorithme dont la réduction la complexité ne est pas dominé par l'algorithme de réduction résultant. Par exemple, une algorithme de sélection pour trouver la médiane dans une liste non triés consiste à trier d'abord la liste (la partie cher) et puis en tirant l'élément central dans la liste triée (la partie pas cher). Cette technique est également connu que de transformer et de conquérir.
- Recherche et dénombrement. Beaucoup de problèmes (comme le jeu d'échecs ) peuvent être modélisés comme des problèmes sur graphiques. Un graphe algorithme d'exploration spécifie les règles pour se déplacer un graphique et est utile pour de tels problèmes. Cette catégorie comprend également algorithmes de recherche, branche et le dénombrement lié et retour en arrière.
- Le paradigme probabiliste et heuristique. Algorithmes appartenant à cette classe correspondent à la définition d'un algorithme plus lâche.
- Algorithmes probabilistes sont ceux qui font des choix au hasard (ou pseudo-aléatoire); pour certains problèmes, il peut en effet être prouvé que les solutions les plus rapides doivent impliquer une certaine aléatoire.
- Les algorithmes génétiques tentent de trouver des solutions aux problèmes en imitant biologiques évolutives processus, avec un cycle de mutations aléatoires produisant des générations successives de «solutions». Ainsi, ils émulent reproduction et "la survie du plus apte». En programmation génétique, cette démarche se étend à des algorithmes, en considérant l'algorithme lui-même comme une «solution» à un problème.
- Algorithmes heuristiques, dont la mission générale est de ne pas trouver une solution optimale, mais une solution approximative où le temps ou les ressources sont limitées. Ils ne sont pas pratiques pour trouver des solutions parfaites. Un exemple de ceci serait recherche locale, recherche tabou, ou algorithmes de recuit simulé, une classe d'algorithmes probabilistes heuristiques qui varient la solution d'un problème par une quantité aléatoire. Le nom " recuit simulé »fait allusion à l'expression métallurgique qui signifie que le chauffage et le refroidissement de métal pour atteindre la liberté de défauts. Le but de la variance aléatoire est de trouver près de globalement solutions optimales plutôt que ceux simplement localement optimales, l'idée étant que l'élément aléatoire sera être diminué par l'algorithme se établit à une solution.
Classification par domaine d'études
Chaque domaine de la science a ses propres problèmes et des besoins des algorithmes efficaces. Les problèmes liés à un champ sont souvent étudiés ensemble. Certaines classes exemples sont algorithmes de recherche, algorithmes de tri, fusionner algorithmes, algorithmes numériques, algorithmes de graphe, algorithmes de chaîne, algorithmes géométriques de calcul, des algorithmes combinatoires , l'apprentissage machine, la cryptographie , les algorithmes de compression de données et techniques de l'analyse.
Les champs tendent à se chevaucher les uns avec les autres, et les progrès de l'algorithme dans un domaine peuvent améliorer ceux des autres, parfois sans aucun rapport, les champs. Par exemple, la programmation dynamique a été inventé pour l'optimisation de la consommation des ressources dans l'industrie, mais est maintenant utilisé pour résoudre un large éventail de problèmes dans de nombreux domaines.
Classification par la complexité
Les algorithmes peuvent être classés par la quantité de temps nécessaire pour compléter rapport à leur taille d'entrée. Il ya une grande variété: certains algorithmes complets en temps linéaire par rapport à la taille d'entrée, certains le font dans une quantité exponentielle du temps, ou pire encore, et certains ne ont jamais se arrêter. En outre, certains problèmes peuvent avoir de multiples algorithmes de complexité différente, tandis que d'autres problèmes pourraient avoir aucun algorithmes ou aucun des algorithmes efficaces connus. Il existe également des problèmes de mappages d'autres problèmes. De ce fait, il se est révélé être plus approprié pour classer les problèmes eux-mêmes au lieu des algorithmes en classes d'équivalence en fonction de la complexité des meilleurs algorithmes possibles pour eux.
Classification par la puissance de calcul
Une autre façon de classer les algorithmes est par la puissance de calcul. Cela se fait habituellement en considérant une certaine collection (classe) d'algorithmes. Une classe d'algorithmes récursif est celui qui comprend des algorithmes pour toutes les fonctions calculables Turing. En regardant classes d'algorithmes permet la possibilité de restreindre les ressources informatiques disponibles (temps et mémoire) utilisées dans un calcul. Une classe subrecursive d'algorithmes est celui dans lequel pas toutes les fonctions calculables Turing peuvent être obtenus. Par exemple, les algorithmes qui se exécutent dans polynomiale suffit pour de nombreux types importants de calcul, mais ne épuisent pas toutes les fonctions calculables de Turing. Les algorithmes de classe mises en œuvre par fonctions récursives primitives est une autre classe subrecursive.
Burgin (2005, p. 24) utilise une définition généralisée des algorithmes qui détend l'exigence commune que la sortie de l'algorithme qui calcule une fonction doit être déterminée après un nombre fini d'étapes. Il définit aa classe d'algorithmes super-récursif "une classe d'algorithmes dans lesquels il est possible de calculer les fonctions non calculables par une machine de Turing" (Burgin 2005, p. 107). Ceci est étroitement lié à l'étude de méthodes de Hypercalcul.
Questions juridiques
Algorithmes, par eux-mêmes, ne sont généralement pas brevetables. Dans le États-Unis , une réclamation composé uniquement de simples manipulations de concepts abstraits, des chiffres ou des signaux ne constituent pas des "processus" (USPTO 2006) et donc algorithmes ne sont pas brevetables (comme dans Gottschalk v. Benson). Cependant, les applications pratiques des algorithmes sont parfois brevetable. Par exemple, dans Diamond c. Diehr, l'application d'un simple, rétroaction algorithme pour aider à la cuisson de de caoutchouc synthétique a été jugée brevetable. Le brevetabilité des logiciels est très controversée, et il ya des brevets très critiquée impliquant des algorithmes, en particulier les algorithmes de compression de données, tels que Unisys ' Brevet LZW.
En outre, certains algorithmes cryptographiques ont des restrictions à l'exportation (voir l'exportation de la cryptographie).
Histoire: le développement de la notion de "algorithme"
Origine du mot
L'algorithme de mot vient du nom de la 9ème siècle Mathématicien persan Abu Abdullah Muhammad ibn Musa al-Khwarizmi dont les œuvres introduites chiffres indiens et concepts algébriques. Il a travaillé dans Bagdad à l'époque où il était le centre d'études et des échanges scientifiques. Le mot algorism origine ne visait que les règles de l'exécution arithmétique utilisant Chiffres arabes, mais évolué via la traduction latine européenne du nom de al-Khwarizmi dans algorithme par le 18ème siècle. Le mot a évolué pour inclure toutes les procédures définies pour résoudre des problèmes ou l'exécution de tâches.
Symboles discrets et distinguables
Tally-marques: Pour garder une trace de leurs troupeaux, leurs sacs de grain et leur argent les anciens utilisés décompte: accumuler des pierres ou des marques rayés sur des bâtons, ou de faire des symboles discrets dans l'argile. Grâce à l'utilisation babylonienne et égyptienne de marques et symboles, éventuellement chiffres romains et le boulier évolué (Dilson, p.16-41). Tally marques apparaissent en bonne place dans unaire arithmétique du système de numération utilisé dans Machine de Turing et Post-machine de Turing calculs.
Manipulation de symboles comme «fictifs» pour les numéros: algèbre
Le travail des anciens géomètres grecs, mathématicien perse Al-Khwarizmi (souvent considéré comme le "père de l'algèbre »), et les mathématiciens d'Europe occidentale ont abouti à Leibniz notion de l 'de la calcul ratiocinator (ca 1680):
- "Un bon siècle et demi d'avance sur son temps, Leibniz proposé une algèbre de la logique, une algèbre qui précise les règles pour manipuler des concepts logiques de la manière que l'algèbre ordinaire précise les règles de manipulation de chiffres» (Davis, 2000: 1)
Artifices mécaniques avec des états discrets
L'horloge: Bolter attribue l'invention de la à poids horloge comme «L'invention touche [de l'Europe au Moyen Age]", en particulier la échappement à verge <(Bolter 1984: 24) qui nous fournit avec le tic et le tac d'une horloge mécanique. "La machine automatique précise" (Bolter 1984: 26) a conduit immédiatement au «mécanique automates "à partir du XIIIe siècle et enfin aux« machines de calcul "- la Moteur de différence et moteurs d'analyse de Charles Babbage et la comtesse Ada Lovelace (Bolter p.33-34, p.204-206).
métier à tisser Jacquard, cartes perforées Hollerith, télégraphie et la téléphonie - le relais électromécanique: Bell et Newell (1971) indiquent que la métier Jacquard (1801), précurseur de Cartes Hollerith (cartes perforées, 1887), et «technologies de commutation téléphonique» étaient les racines d'un arbre menant à l'élaboration des premiers ordinateurs (Bell et Newell schéma p. 39, cf Davis 2000). Vers le milieu des années 1800, le télégraphe, le précurseur du téléphone, était en usage dans le monde entier, son codage discrète et distinguée de lettres comme «points et de traits" un son commun. À la fin des années 1800, le téléscripteur (des années 1870 de CA) a été utilisé, comme ce était l'usage de Cartes Hollerith dans le recensement américain de 1890. Puis vint le Téléscripteur (ca 1910) avec son usage de papier perforé Code Baudot sur bande.
Téléphone-réseaux de commutation électromécanique relais (inventé 1835) était derrière le travail de George Stibitz (1937), l'inventeur du dispositif d'addition numérique. Comme il a travaillé dans les laboratoires Bell, il a observé l'utilisation "lourde" de calculatrices mécaniques avec des engrenages. "Il est allé un soir en 1937 l'intention de tester son idée .... Lorsque le bricolage était terminée, Stibitz avait construit un dispositif d'addition binaire". (Valley Nouvelles, p. 13).
Davis (2000) observe l'importance particulière du relais électromécanique (avec ses deux «états binaires"ouvertesetfermées):
- Ce fut seulement avec le développement, en commençant dans les années 1930, des calculatrices électromécaniques utilisant des relais électriques, que les machines ont été construites ayant la portée Babbage avait imaginé. »(Davis, p. 14).
Mathématiques pendant les années 1800 jusqu'au milieu des années 1900
Symboles et règles : Dans une succession rapide les mathématiques de George Boole (1847, 1854), Gottlob Frege (1879), et Giuseppe Peano (1888-1889) a réduit l'arithmétique à une séquence de symboles manipulés par des règles. De Peano Les principes de l'arithmétique, présentés par une nouvelle méthode (1888) était "la première tentative d'axiomatisation des mathématiques dans un langage symbolique" (van Heijenoort: 81ff).
Mais Heijenoort donne Frege (1879) cette félicitations: Frege est «peut-être le travail le plus important jamais écrit dans la logique ... dans laquelle nous voyons un.» «Langue de formule», qui est uncharacterica lingua, une langue écrite avec des symboles spéciaux , "pour la pensée pure», qui est, sans fioritures rhétoriques ... construit à partir de symboles spécifiques qui sont manipulés conformément aux règles définies "(van Heijenoort: 1). Le travail de Frege était encore simplifiée et amplifiée parAlfred North Whitehead etBertrand Russelldans leurPrincipia Mathematica (1910-1913).
Les paradoxes : Dans le même temps un certain nombre de paradoxes troublants apparu dans la littérature, en particulier le paradoxe Burali-Forti (1897), le paradoxe Russell (1902-1903), et de la Richard Paradox (Dixon 1906, cf Kleene 1952: 36 -40). Les considérations qui en résultent ont conduit à l'article de Kurt Gödel (1931) - il cite spécifiquement le paradoxe du menteur - qui réduit complètement les règles de la récursivité pour les numéros.
Calculabilité effective : Dans un effort pour résoudre le Entscheidungsproblem défini précisément par Hilbert en 1928, les mathématiciens première série sur le point de définir ce que l'on entend par «méthode» ou «calcul efficace» ou «calculabilité effective" (ie, un calcul qui réussirait ). Dans une succession rapide qui suit est apparu: Alonzo Church, Stephen Kleene et de JB Rosser λ-calcul, (note cf dans Alonzo Church 1936a: 90, 1936b: 110) une définition finement aiguisé de «récursivité générale" du travail de Gödel agissant sur suggestions de Jacques Herbrand (les conférences de cf de Gödel Princeton de 1934) et des simplifications ultérieures par Kleene (1935-6: 237ff, 1943: 255ff). La preuve de l'église (1936: 88ff) que le Entscheidungsproblem était insoluble, la définition de Emil Poster de calculabilité effective en tant que travailleur stupidement suivant une liste d'instructions pour aller à gauche ou à droite à travers une séquence de pièces et bien qu'il soit la marque ou effacer un papier ou d'observer la papier et faire un oui-non décision au sujet de la prochaine instruction (cf "Formulation I", Poster 1936: 289-290). Alan Turing preuve s 'des que le Entscheidungsproblem était insoluble par l'utilisation de son "a- [matiquement] la machine "(Turing 1936-7: 116ff) - en effet presque identique à Postes" formulation ", J. La définition de Barkley Rosser de «méthode efficace" en termes de "une machine" (Rosser 1939: 226). La proposition de SC Kleene d'un précurseur de la " thèse de l'Eglise "qu'il a appelé" Thèse I "(Kleene 1943: 273-274), et quelques années plus tard Kleene de renommer sa thèse "la thèse de Church" (Kleene 1952: 300, 317) et de proposer des "Thèse de Turing" (Kleene 1952: 376).
Emil Post (1936) et Alan Turing (1936-7, 1939)
Voici une remarquable coïncidence des deux hommes ne sachant pas l'autre, mais un processus décrivant des hommes-comme-ordinateurs travaillant sur des calculs - et ils céder définitions pratiquement identiques.
Emil Post (1936) décrit les actions d'un "ordinateur" (l'être humain) comme suit:
- «... Deux concepts sont impliqués: celui d'unespace de symbolesdans lequel le travail menant de problème pour répondre doit être effectuée, et un inaltérable fixeensemble de directions.
Son espace de symbole serait
- "Une à deux voies suite infinie des espaces ou des boîtes ... Le solveur de problème ou d'un travailleur est de se déplacer et de travailler dans cet espace de symbole, étant capable d'être dans, et opérant dans une boîte, mais à un moment .... une boîte est pour admettre, mais deux conditions possibles, à savoir, étant vide ou non marqué, et ayant une seule marque en elle, dire d'un trait vertical.
- "Une boîte est d'être choisi et appelé le point de départ. ... Un problème spécifique doit être donnée sous forme symbolique par un nombre fini de boîtes [c.-à-INPUT] est marqué d'un trait. De même la réponse [c.-à- SORTIE] doit être donnée sous forme symbolique par une telle configuration des cases marquées ....
- "Un ensemble de directives applicables à un problème général met en place un processus déterministe lorsqu'il est appliqué à chaque problème spécifique. Ce processus prendra fin que quand il vient à la direction de type (C) [ie, STOP]." (U p. 289-290) Voir plus à la machine de Turing Post-
Alan Turing travail de l '(1936, 1939: 160) a précédé celui de Stibitz (1937); on ignore si Stibitz connaissait le travail de Turing. Le biographe de Turing croit que l'utilisation de Turing d'un modèle de machine à écrire comme dérivé d'un intérêt de jeunesse: "Alan avait rêvé d'inventer des machines à écrire comme un garçon; Mme Turing avait une machine à écrire; et il pourrait bien avoir commencé par se demander ce que l'on entend par l'appel d'une machine à écrire «mécanique» (Hodges, p. 96). Compte tenu de la prévalence de morse et la télégraphie, machines de téléscripteur, et télétypes nous pourrions supposer que tous étaient influences .
Turing - son modèle de calcul est maintenant appelé une machine de Turing - commence, comme l'a fait Post, avec une analyse d'un ordinateur humaine qu'il rogne à une simple série de mouvements de base et des "états d'âme". Mais il continue un peu plus loin et crée une machine comme un modèle de calcul de nombres (Turing 1936-7: 116).
- "Computing est normalement fait en écrivant certains symboles sur papier. Nous pouvons supposer ce document est divisé en carrés comme le livre de l'arithmétique d'un enfant .... Je suppose alors que le calcul est effectué sur papier à une dimension, à savoir, sur une bande divisée en carrés. Je vais aussi supposer que le nombre de symboles qui peuvent être imprimés est finie ....
- "Le comportement de l'ordinateur à tout moment est déterminé par les symboles dont il est l'observation, et son" état d'esprit "à ce moment. On peut supposer qu'il ya un B lié au nombre de symboles ou des carrés que l'ordinateur peut observer à un moment. Si il veut observer de plus, il doit utiliser observations successives. Nous allons également supposer que le nombre d'états d'esprit qui doivent être pris en compte est finie ...
- "Imaginons que les opérations effectuées par l'ordinateur pour être divisés en« opérations simples »qui sont tellement élémentaire qu'il est pas facile de les imaginer outre divisé" (Turing 1936-7: 136).
La réduction de Turing donne le résultat suivant:
- "Les opérations simples doivent donc comprendre:
- "(A) Modifications du symbole sur une des places observés
- "(B) Modifications de l'une des places observés à un autre carré dans L carrés de l'une des places observés précédemment.
"Il se peut que certains de ces changements invoquent nécessairement un changement d'état d'esprit La seule opération la plus générale doit donc être pris pour être l'un des suivants.:
- "(A) Un changement possible (a) du symbole avec un éventuel changement de l'état d'esprit.
- "(B) Un changement possible (b) de carrés observés, avec un éventuel changement de l'état d'esprit"
- "Nous pouvons maintenant construire une machine pour faire le travail de cet ordinateur." (Turing 1936-7: 136)
Quelques années plus tard, Turing a élargi son analyse (thèse, définition) avec cette expression énergique de celui-ci:
- "Une fonction est dite" effectivey calculable "si ses valeurs peuvent être trouvées par quelque procédé purement mécanique. Bien qu'il soit assez facile d'obtenir une compréhension intuitive de cette idée, il est souhaitable d'avoir neverthessless certains, la définition exprimable mathématique plus précis ... [il parle de l'histoire de la définition à peu près tel que présenté ci-dessus par rapport à Gödel, Herbrand, Kleene, Église, Turing et Post]... Nous pouvons prendre cette déclaration littéralement, la compréhension par un procédé purement mécanique qui pourrait être effectuée par une machine. Il est possible de donner une description mathématique, dans une certaine forme normale, des structures de ces machines. Le développement de ces idées conduit à la définition de l'auteur d'une fonction calculable, et à une identification de la calculabilité † avec calculabilité effective....
- "† Nous allons utiliser l'expression« fonction calculable »pour signifier une fonction calculable par une machine, et nous laisser" efficacement calculabile (Turing 1939: 160) "se réfèrent à l'idée intuitive sans identification particulière à l'une quelconque de ces définitions."
JB Rosser (1939) et SC Kleene (1943)
J. Barkley Rosserdéfini hardiment une «méthode [mathématique] efficace» de la manière suivante (en gras dans le texte):
- «Méthode efficace» est utilisé ici dans le sens assez particulier d'une méthode chaque étape de ce qui est précisément déterminée, et qui est certain pour produire la réponse en un nombre fini d'étapes. Avec cette signification spéciale, trois définitions précises différents ont été donnés à ce jour [sa note n ° 5; voir la discussion immédiatement ci-dessous]. Le plus simple d'entre eux à l'état (en raison de la Poste et de Turing) dit essentiellement que. une méthode efficace de résolution de certains ensembles de problèmes existe si l'on peut construire une machine qui sera ensuite résoudre tout problème de l'ensemble sans aucune intervention humaine au-delà de l'insertion de la question et (plus tard) la lecture de la réponse . Tous les trois définitions sont équivalentes, de sorte qu'il n'a pas d'importance lequel est utilisé. En outre, le fait que tous les trois sont équivalentes est un argument très fort pour la justesse de l'une quelconque ". (Rosser 1939: 225-6)
La note N ° Rosser 5 références du travail de (1) Église et Kleene et leur définition de λ-définissabilité, dans l'utilisation de Eglise particulière de celui-ci dans son un problème insoluble du primaire Théorie des Nombres (1936); (2) Herbrand et Gödel et leur utilisation de la récursivité dans l'utilisation de Gödel notamment dans son fameux papier Sur Formellement indécidables Propositions de Principia Mathematica et des systèmes connexes I (1931); et (3) Post (1936) et Turing (1936-7) dans leur mécanisme modèles de calcul.
Stephen C. Kleene définie comme sa désormais célèbre "Thèse I" connu comme "la thèse de Church-Turing ". Mais il l'a fait dans le cadre ci-dessous (en caractères gras dans l'original):
- "12.théories algorithmiques... En mettant en place une théorie algorithmique complète, ce que nous faisons est de décrire une procédure, exécutable pour chaque ensemble de valeurs des variables indépendantes, la procédure qui se termine nécessairement et de manière telle que le résultat que nous pouvons lu une réponse définitive, «oui» ou «non» à la question, "est la valeur de prédicat vrai?" "(Kleene 1943: 273)
Histoire après 1950
Un certain nombre d'efforts ont été dirigés vers affinement de la définition de «algorithme», et l'activité est en cours en raison de problèmes environnantes, en particulier, fondements des mathématiques (en particulier la Thèse de Church-Turing) et la philosophie de l'esprit (en particulier les arguments autour de l'intelligence artificielle). Pour plus, voir caractérisations algorithme.