
Cache da CPU
Você sabia ...
Esta seleção wikipedia foi escolhido por voluntários que ajudam Crianças SOS da Wikipedia para este Seleção Wikipedia para as escolas. patrocínio SOS Criança é legal!
A cache da CPU é um cache usado pela unidade de processamento central de um computador para reduzir o tempo médio necessário para aceder memória. O cache é uma memória menor, mais rápido que armazena cópias dos dados do mais utilizado locais de memória principal. Enquanto a maioria dos acessos de memória são armazenados em cache locais de memória, a média latência de acessos de memória vai estar mais perto da latência de cache do que a latência de memória principal.
Visão global
Quando o processador precisa ler ou escrever para uma localização na memória principal, que primeiro verifica se uma cópia desses dados é no cache. Se assim for, o processador lê imediatamente ou escreve para o cache, o que é muito mais rápido do que ler ou escrever para a memória principal.
A maioria das modernas CPUs de desktop e servidor ter pelo menos três caches independentes: um cache de instruções para acelerar a instrução executável buscar, um cache de dados para acelerar dados buscar e armazenar, e um tampão de consulta da tradução (TLB) usado para acelerar a tradução de virtual para físico endereços para ambas as instruções executáveis e dados. O cache de dados é normalmente organizado como uma hierarquia de mais níveis de cache (L1, L2, etc .; ver caches Multi-level ).
Entradas de cache
Os dados são transferidos entre a memória cache e em blocos de tamanho fixo, chamadas linhas de cache. Quando uma linha de cache é copiado da memória para o cache, uma entrada de cache é criado. A entrada de cache irá incluir os dados copiados, bem como o local de memória solicitada (agora chamado de tag).
Quando o processador precisa ler ou escrever uma localização na memória principal, ele primeiro verifica para uma entrada correspondente no cache. As verificações de cache para o conteúdo do local de memória solicitada em todas as linhas de cache que podem conter esse endereço. Se o processador verifica que o local de memória estiver no cache, um cache hit ocorreu (caso contrário, um erro de cache). No caso de:
- um acerto de cache, o processador imediatamente lê ou grava os dados na linha de cache.
- um erro de cache, o cache aloca uma nova entrada, e em cópias de dados da memória principal. Em seguida, o pedido é cumprida a partir dos conteúdos do cache.
Desempenho Cache
A proporção de acessos que resultar num sucesso de cache é conhecida como a taxa de acerto, e pode ser uma medida da eficácia do cache para um determinado programa ou algoritmo.
Leia-acidentes atrasar a execução porque exigem que os dados sejam transferidos da memória muito mais lento do que o próprio cache. Escrever acidentes podem ocorrer sem tal pena, uma vez que o processador pode continuar a execução enquanto os dados são copiados para a memória principal em segundo plano.
Caches de instrução são semelhantes aos caches de dados, mas a CPU executa apenas acessos de leitura (instrução de busca) para o cache de instrução. (Com Arquitetura Harvard e Arquitectura modificados Harvard CPUs, instruções e dados caches podem ser separadas, com maior rendimento, mas também podem ser combinados para reduzir a sobrecarga de hardware.)
Políticas de substituição
A fim de abrir espaço para a nova entrada em um erro de cache, o cache pode ter que expulsar uma das entradas existentes. A heurística que ele usa para escolher a entrada para expulsar é chamado de política de substituição. O problema fundamental com qualquer política de substituição é que deve prever o que é menos susceptível de ser utilizado no futuro entrada de cache existente. Prever o futuro é difícil, por isso não há maneira perfeita de escolher entre a variedade de políticas de substituição disponíveis.
Uma política de substituição popular, menos recentemente usada (LRU), substitui a entrada menos recentemente acessados.
Marcação algumas faixas de memória como não-cacheable pode melhorar o desempenho, evitando o armazenamento em cache das regiões de memória que são raramente re-acessadas. Isto evita a sobrecarga de carregar algo no cache, sem ter qualquer reutilização.
- Entradas de cache também pode ser desativado ou bloqueado, dependendo do contexto.
Políticas de escrita
Se os dados são gravados no cache, em algum momento ele deve também ser escrita para a memória principal. O momento desta gravação é conhecida como a política de gravação.
- Em um write-through cache, cada gravação para o cache faz com que uma gravação para a memória principal.
- Alternativamente, numa write-back ou cache de cópia de segurança, as gravações não são imediatamente espelhado para a memória principal. Em vez disso, o cache rastreia quais locais foram escritos sobre (esses locais são marcadas sujo). Os dados nesses locais são escritos de volta para a memória principal apenas quando os dados são expulsos do cache. Por esta razão, uma falha de leitura em um cache write-back às vezes pode exigir dois acessos à memória de serviço: um para primeiro escrever o local sujo para a memória e depois outro para ler a nova localização da memória.
Existem políticas intermediários também. O cache pode ser write-through, mas as gravações podem ser mantidos em uma fila de armazenamento de dados temporariamente, geralmente para que várias lojas podem ser processados em conjunto (que pode reduzir paradas de ônibus e melhorar a utilização de ônibus).
Os dados na memória principal sendo em cache pode ser mudado por outras entidades (por exemplo, usando periféricos acesso direto à memória ou processador multi-core), caso em que a cópia no cache pode se tornar out-of-date ou obsoleto. Em alternativa, quando a CPU em um processador multi-core atualiza os dados no cache, cópias de dados em caches associadas a outros núcleos se tornará obsoleto. Os protocolos de comunicação entre os gerentes de cache que manter os dados consistentes são conhecidos como protocolos de coerência de cache.
Bancas de CPU
O tempo necessário para buscar uma linha de cache da memória (ler latência) é importante porque a CPU vai ficar fora das coisas para fazer enquanto espera para a linha de cache. Quando uma CPU atinge este estado, ele é chamado de uma tenda.
Como CPUs tornar-se mais rápido, barracas devido a falta de cache deslocar mais potencial computação; processadores modernos podem executar centenas de instruções no tempo necessário para buscar uma única linha de cache de memória principal. Várias técnicas têm sido empregues para manter o processador ocupado durante este tempo.
- Out-of-order CPUs (processadores Pentium Pro e designs mais tarde Intel, por exemplo) tentativa de executar instruções independentes após a instrução que está à espera dos dados de cache de miss.
- Outra tecnologia, utilizado por muitos processadores, é multithreading simultânea (SMT), ou - na terminologia da Intel - hyper-threading (HT), que permite que um segmento alternativo de usar o núcleo da CPU, enquanto um primeiro segmento aguarda dados de vir de memória principal.
Estrutura de entrada de cache
Entradas de linha de cache geralmente têm a seguinte estrutura:
| etiqueta | bloco de dados | bandeira bits |
O bloco de dados (linha de cache) contém os dados reais obtido a partir da memória principal. O tag contém (parte de) o endereço dos dados reais obtido a partir da memória principal. Os bits de bandeira são discutidos abaixo.
O "tamanho" do cache é a quantidade de dados da memória principal que pode conter. Este tamanho pode ser calculado como o número de bytes armazenados em cada bloco de dados de vezes o número de blocos armazenados na memória cache. (O número de tag e bandeira pedaços é irrelevante para este cálculo, embora não afetam a área física de um cache).
Um endereço de memória é dividida eficaz ( MSB para LSB) na tag, o índice eo bloco de deslocamento.
| etiqueta | índice | compensada bloco |
O índice descreve qual linha cache (que linha de cache) que os dados foram colocados em. O comprimento índice é 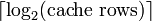 bocados. O deslocamento de blocos especifica os dados desejado dentro do bloco de dados armazenados dentro da linha de cache. Normalmente, o endereço é eficaz em bytes, de modo que o afastamento do comprimento do bloco é
bocados. O deslocamento de blocos especifica os dados desejado dentro do bloco de dados armazenados dentro da linha de cache. Normalmente, o endereço é eficaz em bytes, de modo que o afastamento do comprimento do bloco é  bocados. O tag contém os bits mais significativos do endereço, que são verificadas em relação a linha atual (a linha foi recuperada pelo índice) para ver se ele é o que precisamos ou de outro, local de memória irrelevante que passou a ter os mesmos bits de índice como a que queremos. O comprimento em bits é tag
bocados. O tag contém os bits mais significativos do endereço, que são verificadas em relação a linha atual (a linha foi recuperada pelo índice) para ver se ele é o que precisamos ou de outro, local de memória irrelevante que passou a ter os mesmos bits de índice como a que queremos. O comprimento em bits é tag 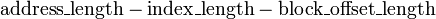 .
.
Alguns autores referem-se ao bloco de deslocamento como simplesmente a "compensação" ou o "deslocamento".
Exemplo
O Pentium 4 original tinha um 4-way cache associativo dados L1 de 8 KB de tamanho com blocos de cache de 64 bytes. Assim, existem 8 KB / 64 = 128 blocos de cache. Se é 4-way set associative, isto implica 128/4 = 32 conjuntos (e, portanto 2 ^ 5 = 32 diferentes índices). Há 64 = 2 ^ 6 possíveis compensações. Já que o endereço CPU é de 32 bits, o que implica 32 = 21 + 5 + 6, e, portanto, 21 bits de campo tag. O Pentium 4 original também tinha um 8-way set associative cache L2 integrado de tamanho 256 KB de cache com 128 blocos de bytes. Isto implica 32 = 17 + 8 + 7, e, por conseguinte, 17 bits de campo de etiqueta.
Bandeira pedaços
Um cache de instrução exige apenas um pouco de bandeira por entrada de linha de cache: um pouco válido. O bit de validade indica se ou não um bloco cache foi carregado com dados válidos.
No momento da ligação, o hardware define todos os bits válidos em todos os esconderijos para "inválido". Alguns sistemas também definir um pouco válida para "inválido" em outras ocasiões, tais como quando multi-mestre ônibus bisbilhotando hardware no cache de um processador ouve um endereço de transmissão de algum outro processador, e percebe que certos blocos de dados no cache local são agora obsoleto e deve ser marcada como inválida.
Um cache de dados normalmente exige dois bits bandeira por entrada de linha de cache: um pouco válida e também uma pouco suja. O pouco suja indica se esse bloco foi inalterado desde que foi lido a partir da memória principal - "limpo", ou se o processador tem escrito dados para esse bloco (eo novo valor ainda não fez todo o caminho para a memória principal) - "sujo".
Associatividade
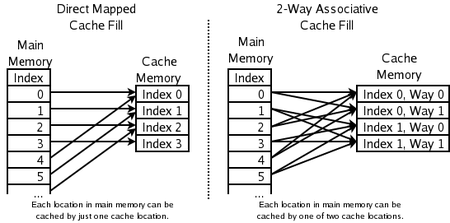
A política de substituição decide onde na cache uma cópia de uma entrada específica de memória principal irá. Se a política de substituição é livre para escolher qualquer das entradas do cache para armazenar a cópia, o cache é chamado totalmente associativo. No outro extremo, se cada entrada na memória principal pode ir em apenas um lugar no cache, o cache é direta mapeada. Muitos caches implementar uma solução de compromisso em que cada entrada na memória principal pode ir para qualquer um dos N lugares no cache, e são descritos como conjunto N-way associativo. Por exemplo, o cache de dados de nível-1 numa AMD Athlon é 2-way set associativo, o que significa que qualquer determinado local na memória principal pode ser armazenada em cache em um dos dois locais no cache de dados de nível 1.
Associatividade é um troca. Se há dez lugares a que a política de substituição poderia ter mapeado uma localização de memória, em seguida, para verificar se esse local é no cache, dez entradas de cache deve ser pesquisado. Verificando mais lugares leva mais poder, área de chips, e potencialmente tempo. Por outro lado, com caches mais associamento sofrem menos acidentes (ver erros de conflito, a seguir), de modo que os resíduos de CPU menos tempo a ler a partir da memória principal lenta. A regra de ouro é que a duplicação da associatividade, de direta mapeado para 2-way, ou a partir de 2-way a 4-way, tem o mesmo efeito sobre a taxa de sucesso como a duplicação do tamanho do cache. Associatividade aumenta para além de 4 vias tem muito menos efeitos sobre a taxa de acerto, e geralmente são feitas por outras razões (ver aliasing virtual, abaixo).
A fim de pior, mas simples para melhor, mas complexa:
- o cache mapeado direta - Os melhores (mais rápido) hit vezes, e por isso o melhor tradeoff para caches "grandes"
- 2-way cache associativo
- 2-way de cache associativo distorcida - O melhor tradeoff para caches cujos tamanhos estão na faixa-4K 8K bytes.
- 4-way cache associativo
- o cache completamente associativa - os melhores (mais baixa) taxas de falta, e assim o melhor tradeoff quando a pena de perder é muito elevado
Cache de Direct-mapeada
Aqui cada local na memória principal só pode ir em uma entrada no cache. Ele não tem uma política de substituição, como tal, já que não há escolha de qual conteúdo da entrada de cache para expulsar. Isto significa que se dois locais mapeados para a mesma entrada, eles podem bater continuamente uns aos outros. Embora mais simples, um cache diretamente mapeada precisa ser muito maior do que um associativo para proporcionar um desempenho comparável, e é mais imprevisível.
2-way cache associativo
Se cada posição na memória principal pode ser armazenada em cache em um dos dois locais no cache, uma pergunta lógica é: qual dos dois O esquema mais simples e mais comumente utilizado, mostrado no diagrama da direita acima, é usar o bits menos significativos do índice do local de memória como o índice para a memória cache, e de ter duas entradas para cada índice. Uma das vantagens deste sistema é que as tags armazenados no cache não tem que incluir a parte do endereço de memória principal que está implícito pelo índice da memória cache. Uma vez que as marcas de cache tem menos bits, eles tomam menos área no chip microprocessador e pode ser lido e comparado mais rápido. Também LRU é especialmente simples uma vez que apenas um bit precisa de ser armazenado para cada par.
Execução especulativa
Uma das vantagens de um cache mapeado directa é que permite simples e rápido especulação. Uma vez que o endereço tenha sido computados, o índice de um esconderijo que pode ter uma cópia desse local na memória é conhecido. Essa entrada de cache pode ser lido, eo processador pode continuar a trabalhar com esses dados antes de terminar a verificação de que o tag na verdade corresponde ao endereço solicitado.
A ideia de ter o processador de usar os dados armazenados antes da conclusão do jogo etiqueta pode ser aplicada a associativas caches bem. Um subconjunto da tag, chamado de uma dica, pode ser usado para escolher apenas um dos possíveis mapeamento de entradas de cache para o endereço solicitado. A entrada seleccionada por a dica pode, então, ser utilizado em paralelo com a verificação da marcação completa. A técnica dica funciona melhor quando usado no contexto de tradução de endereços, como explicado abaixo.
2-way de cache associativo enviesada
Outros esquemas têm sido sugeridas, tais como a cache inclinada, onde o índice de modo directo é 0, como acima, mas o índice de forma 1 é formada com um função hash. A função hash boa tem a propriedade que aborda que o conflito com o mapeamento direto não tendem a conflito quando mapeada com a função hash, e por isso é menos provável que um programa vai sofrer de um número inesperadamente grande de conflito falha devido a um acesso patológico padrão. A desvantagem é a latência adicional de computar a função hash. Além disso, quando se trata tempo para carregar uma nova linha e despejar uma linha de idade, pode ser difícil determinar qual linha existente foi menos utilizado recentemente, porque a nova linha conflitos com dados em diferentes índices em cada sentido; LRU de rastreamento para caches não-enviesadas geralmente é feito em uma base per-definido. No entanto, caches distorcidas associativa ter grandes vantagens sobre as set-associativa convencionais.
Cache de Pseudo-associativa
Um cache de conjunto associativo verdadeiro testa todas as formas possíveis simultaneamente, usando algo parecido com um memória endereçável de conteúdo. Um cache pseudo-associativa testa cada possível uma forma de cada vez. Um cache de hash-repetição e um cache-coluna associativo são exemplos de cache do pseudo-associativa.
No caso comum de encontrar um hit no primeiro caminho testado, um cache de pseudo-associativa é tão rápido quanto um cache diretamente mapeada. Mas tem uma taxa de erro muito mais baixa do que um cache conflito direto-mapeados, mais perto da taxa de perda de um cache completamente associativa.
Falha de cache
Um erro de cache refere-se a uma tentativa falhada para ler ou escrever um pedaço de dados no cache, o que resulta em um acesso de memória principal com muito mais tempo de latência. Existem três tipos de erros de cache: instrução lido falta, os dados lidos falta, e falta escrever dados.
Um cache de leitura falta de um cache de instrução geralmente faz com que o mais demora, porque o processador, ou pelo menos o segmento de execução, tem de esperar (tenda) até que a instrução é extraído da memória principal.
Um cache de leitura falta de um cache de dados geralmente provoca menos atraso, porque as instruções não dependentes da leitura do cache pode ser emitido e continuar a execução até que os dados são retornados a partir da memória principal, e as instruções dependentes podem continuar a execução.
Um erro de cache de gravação para um cache de dados geralmente faz com que o mínimo atraso, porque a gravação pode ser colocado em fila e há poucas limitações na execução de instruções subseqüentes. O processador pode continuar até que a fila está cheia.
A fim de diminuir o cache taxa de falta, uma grande quantidade de análise foi feita sobre o comportamento de cache em uma tentativa de encontrar a melhor combinação de tamanho, associatividade, tamanho do bloco, e assim por diante. Sequências de referências de memória executadas por programas de benchmark são salvos como vestígios de endereço. As análises subsequentes simular diversos modelos possíveis de cache diferentes sobre a presença desses vestígios de endereços longos. Fazer o sentido de como as muitas variáveis afetam a taxa de acerto de cache pode ser um pouco confuso. Uma contribuição significativa para esta análise foi feita por Mark Hill, que se separou acidentes em três categorias (conhecidos como os três Cs):
- Acidentes obrigatórias são aquelas causadas por acidentes a primeira referência a uma localização na memória. O tamanho do cache e associatividade não fazem diferença para o número de acidentes obrigatórias. Prefetching pode ajudar aqui, como se pode armazenar em cache maior tamanhos de bloco (que são uma forma de prefetching). Acidentes obrigatórios são muitas vezes referidos como acidentes frias.
- Faltas de capacidade são aqueles acidentes que ocorrem independentemente da associatividade ou tamanho do bloco, unicamente devido ao tamanho finito do cache. A curva de taxa de perda de capacidade em relação tamanho do cache dá alguma medida da localidade temporal de um fluxo de referência particular. Note-se que não existe uma noção útil de um cache "cheio" ou "vazio" ou "perto de sua capacidade": caches de CPU quase sempre têm quase todos os linha preenchida com uma cópia de alguma linha na memória principal, e quase todos os alocação de um novo linha requer o despejo de uma linha de idade.
- Acidentes de conflito são os acidentes que poderiam ter sido evitadas, se o cache não despejada uma entrada mais cedo. Acidentes de conflito podem ser subdivididas em acidentes de mapeamento, que são inevitáveis dada uma determinada quantidade de associatividade, e erra de substituição, que são devidos a vítima a escolha particular da política de substituição.
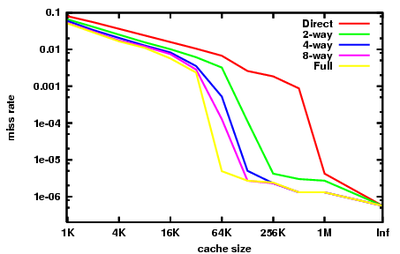
O gráfico à direita resume o desempenho do cache visto na parte inteira do benchmarks SPEC CPU2000, tal como foram recolhidos por Hill e Cantin. Estes benchmarks são destinados para representar o tipo de carga de trabalho que um computador de estação de trabalho de engenharia pode ver em qualquer dia. O leitor deve ter em mente que encontrar benchmarks que são ainda utilmente representante de muitos programas tem sido muito difícil, e sempre haverá programas importantes com comportamento muito diferente do que é mostrado aqui.
Podemos ver os diferentes efeitos dos três Cs neste gráfico.
Na extrema direita, com tamanho de cache rotulado "Inf", temos os acidentes obrigatórias. Se queremos melhorar o desempenho de uma máquina em SPECint2000, aumentando o tamanho do cache para além de 1 MB é essencialmente inútil. Essa é a visão dada pelos acidentes obrigatórias.
O cache de taxa de erro totalmente associativo aqui é quase representante da taxa de falta de capacidade. A diferença é que os dados apresentados são a partir de simulações assumindo uma Política de substituição LRU. Mostrando a taxa de falta de capacidade exigiria um política de substituição perfeito, ou seja, um oráculo que olha para o futuro para encontrar uma entrada de cache que realmente não vai ser atingido.
Note-se que a nossa aproximação da taxa de falta de capacidade cai acentuadamente entre 32 kB e 64 kB. Isto indica que o valor de referência tem um conjunto de trabalho de cerca de 64 kB. Um designer de cache da CPU examinar esta referência terá um forte incentivo para definir o tamanho do cache para 64 kB, em vez de 32 kB. Note-se que, nesta referência, nenhuma quantidade de associatividade pode fazer um cache de 32 kB executar, bem como um 64 kB 4-way, ou até mesmo um 128 KB de cache diretamente mapeada.
Finalmente, note que entre 64 kB e 1 MB, há uma grande diferença entre caches diretos mapeados e totalmente associativos. Esta diferença é a taxa de falta de conflitos. A visão de olhar para as taxas de falta de conflito é que caches secundárias beneficiar muito de alta associatividade.
Este benefício era bem conhecido no final dos anos 80 e início dos anos 90, quando os designers de CPU não poderiam caber grandes caches on-chip, e não poderia obter largura de banda suficiente para tanto a memória de dados de memória cache quando tag cache para implementar alta associatividade em caches off-chip . Hacks Desperate foram tentadas: o MIPS R8000 usada caro off-chip dedicado tag SRAMs, que haviam embarcados comparadores de tags e grandes motoristas nas linhas de jogo, a fim de implementar um 4 MB de cache 4-way associativo. A MIPS R10000 usou chips de memória SRAM comuns para os tags. Tag acesso para ambos os sentidos levou dois ciclos. Para reduzir a latência, o R10000 iria adivinhar qual caminho do cache teria atingido em cada acesso.
Tradução de endereços
A maioria das CPUs de propósito geral implementar alguma forma de memória virtual. Para resumir, cada programa em execução na máquina vê seu próprio simplificado espaço de endereço, que contém código e dados apenas para esse programa. Cada programa utiliza esse espaço de endereço virtual sem consideração para onde ela existe na memória física.
A memória virtual requer o processador para traduzir os endereços virtuais gerados pelo programa em endereços físicos na memória principal. A porção do processador que faz esta conversão é conhecida como a unidade de gerenciamento de memória (MMU). O caminho rápido através da MMU pode executar essas traduções armazenados no tampão de consulta da tradução (TLB), que é um cache de mapeamentos do sistema operacional do tabela de página.
Para os fins da presente discussão, há três características importantes de tradução de endereços:
- Latência: O endereço físico é disponível a partir do MMU algum tempo, talvez alguns ciclos, após o endereço virtual é disponível a partir do gerador de endereços.
- Aliasing: Vários endereços virtuais podem ser mapeados para um único endereço físico. A maioria dos processadores garante que todas as atualizações para esse endereço físico único que acontecerá no fim do programa. Para cumprir essa garantia, o processador deve garantir que apenas uma cópia de um endereço físico reside na cache, em determinado momento.
- Granularidade: O espaço de endereço virtual é dividida em páginas. Por exemplo, a 4 GB de espaço de endereço virtual pode ser cortada em 1.048.576 páginas de 4 kB de tamanho, cada um dos quais podem ser mapeados de forma independente. Pode haver vários tamanhos de página suportados; ver memória virtual para elaboração.
Uma nota histórica: alguns sistemas de memória virtual iniciais foram muito lento, porque eles necessário um acesso para a tabela de páginas (realizada em memória principal) antes de cada acesso programado para a memória principal. Com nenhum caches, esta cortar eficazmente a velocidade da máquina em metade. A primeira cache de hardware usado em um sistema de computador não foi realmente um cache de dados ou instrução, mas sim um TLB.
Caches podem ser divididos em quatro tipos, com base em se o índice de marcação ou correspondem aos endereços físicos ou virtuais:
- Fisicamente indexada, fisicamente marcados (PIPT) caches usar o endereço físico tanto para o índice ea marca. Enquanto isso é simples e evita problemas com aliasing, também é lento, como o endereço físico deve ser pesquisada (que poderia envolver uma falta de TLB e acesso à memória principal), antes que o endereço pode ser pesquisado no cache.
- Praticamente indexada, praticamente com a tag (VIVT) caches usar o endereço virtual, tanto para o índice ea marca. Este esquema de armazenamento em cache pode resultar em pesquisas muito mais rápido, uma vez que a MMU não precisa de ser consultados em primeiro lugar para determinar o endereço físico para um determinado endereço virtual. No entanto, VIVT sofre de problemas de aliasing, onde vários endereços virtuais diferentes podem se referem ao mesmo endereço físico. O resultado é que esses endereços serão armazenadas separadamente apesar referindo-se a mesma memória, causando problemas de coerência. Outro problema é homônimos, onde o mesmo endereço virtual mapeia para vários endereços físicos diferentes. Não é possível distinguir esses mapeamentos apenas olhando para o índice virtual, embora possíveis soluções incluem: limpar o cache depois de um mudança de contexto, forçando espaços de endereço para ser não-sobreposição, marcação do endereço virtual com um ID espaço de endereço (ASID), ou usando tags físicos. Além disso, há um problema que de virtual para físico mapeamentos pode mudar, o que exigiria a lavagem linhas de cache, como o vaso já não seria válida.
- , Fisicamente marcados (VIPT) caches praticamente indexados usar o endereço virtual para o índice eo endereço físico na tag. A vantagem sobre PIPT é menor latência, como a linha de cache pode ser olhou para cima em paralelo com a tradução TLB, no entanto, a marca não pode ser comparado até o endereço físico está disponível. A vantagem sobre VIVT é que desde que a marca tem o endereço físico, o cache pode detectar homônimos. VIPT requer mais bits de marca, como os bits de índice já não representam o mesmo endereço.
- Fisicamente indexada, praticamente com a tag (PIVT) caches são apenas teóricos como eles seria basicamente inútil.
A velocidade dessa recorrência (a latência de carga) é crucial para o desempenho da CPU, e assim mais modernos do nível 1 caches são praticamente indexado, que, pelo menos, permite pesquisa TLB do MMU para prosseguir em paralelo com buscar os dados da RAM cache.
Mas indexação virtual não é a melhor escolha para todos os níveis de cache. O custo de lidar com aliases virtuais cresce com o tamanho do cache, e como resultado, a maioria nível 2 e maiores caches são fisicamente indexados.
Caches têm historicamente utilizado ambos os endereços físicos e virtuais para as tags de cache, embora marcação virtual é agora incomum. Se a pesquisa TLB pode terminar antes da pesquisa de cache RAM, então o endereço físico está disponível a tempo para comparar tag, e não há necessidade de marcação virtual. Grandes esconderijos, então, tendem a ser marcado fisicamente, e apenas pequenas, muito baixos caches de latência são praticamente marcados. Nos últimos processadores de uso geral, a marcação virtual foi substituído por vhints, conforme descrito abaixo.
Problemas homônimo e sinónimos
O cache de que dependa a indexação virtual e marcação torna-se inconsistente após o mesmo endereço virtual é mapeado em diferentes endereços físicos ( homônimo). Isto pode ser resolvido através da utilização de endereços físicos para etiquetagem ou através do armazenamento do espaço de endereço ID na linha de cache. No entanto, a última destas duas abordagens não ajuda contra o problema sinônimo, onde várias linhas de cache acabam armazenando dados para o mesmo endereço físico. Escrevendo para tal localização pode atualizar apenas um local no cache, deixando os outros com dados inconsistentes. Este problema pode ser resolvido usando layouts memória não sobrepostos para espaços de endereços diferentes ou de outra forma o cache (ou parte dele) deve ser liberado quando as mudanças de mapeamento.
Etiquetas virtuais e vhints
A grande vantagem de etiquetas virtuais é que, para caches associativas, eles permitem que o jogo tag para prosseguir antes do virtual para tradução físico é feito. No entanto,
- sondas de coerência e despejos apresentar um endereço físico para a ação. O hardware deve ter alguns meios de converter os endereços físicos em um índice de cache, geralmente por armazenar marcas físicas, bem como as etiquetas virtuais. Para efeitos de comparação, um cache fisicamente marcado não precisa de manter as etiquetas virtuais, que é mais simples.
- Quando um mapeamento virtual para físico é excluído do TLB, entradas de cache com esses endereços virtuais terão de ser liberado de alguma forma. Como alternativa, se as entradas de cache são permitidos em páginas não mapeados pela TLB, em seguida, as entradas terão de ser liberado quando os direitos de acesso para estas páginas são alterados na tabela de página.
É também possível para o sistema operativo para assegurar que não há pseudónimos virtuais são simultaneamente residente na memória cache. O sistema operacional faz com que essa garantia através da aplicação para colorir, que é descrito abaixo. Alguns processadores RISC primeiros (SPARC, RS / 6000) levou esta abordagem. Ele não tem sido utilizado recentemente, como o custo de detectar e expulsar aliases virtuais hardware caiu ea complexidade do software e pena de página para colorir perfeito desempenho aumentou.
Pode ser útil para distinguir as duas funções de etiquetas em um cache associativo: eles são utilizados para determinar qual o modo de entrada configurado para seleccionar, e eles são usados para determinar se o cache de bater ou perdido. A segunda função deve ser sempre correto, mas é admissível que a primeira função de adivinhar, e obter a resposta errada ocasionalmente.
Alguns processadores (por exemplo Sparcs precoces) têm caches com ambas as marcas virtuais e físicos. As etiquetas virtuais são usadas para a seleção maneira, e as marcas físicas são usados para determinar sucesso ou um fracasso. Esse tipo de cache de goza da vantagem de latência de um cache praticamente marcado, ea interface de software simples de um cache fisicamente marcado. Ele tem o custo adicional de etiquetas duplicadas, no entanto. Além disso, durante o processamento de falta, os caminhos alternativos da linha de cache indexados têm de ser sondado para aliases virtuais e todas as correspondências despejadas.
A área adicional (e alguns latência) pode ser mitigado, mantendo dicas virtuais com cada entrada de cache em vez de etiquetas virtuais. Estas pistas são um subconjunto ou hash da etiqueta virtual, e são utilizados para seleccionar o modo de o cache de partida para obter dados e uma marcação física. Como um cache praticamente marcado, pode haver uma correspondência dica mas incompatibilidade tag físico virtual, caso em que a entrada de cache com a dica correspondente deve ser despejada para que acessa o cache após o cache encher neste endereço terá apenas uma partida dica. Desde dicas virtuais têm menos bits do que as etiquetas virtuais que as distinguem umas das outras, um cache praticamente deu a entender sofre mais faltas do que um cache de conflito praticamente marcado.
Talvez a redução definitiva de dicas virtuais podem ser encontradas nos processadores Pentium 4 (Willamette e Northwood núcleos). Nesses processadores a dica virtual é efetivamente 2 bits, eo cache é 4-way set associativo. Efetivamente, o hardware mantém uma permutação simples de endereço virtual para o índice de cache, de modo que nenhuma É necessário conteúdo endereçável memória (CAM) para selecionar o direito um dos quatro maneiras buscado.
Coloração página
Grandes caches fisicamente indexadas (geralmente caches secundários) executado em um problema: o sistema operacional em vez de os controles de aplicativos que páginas colidem um com o outro no cache. As diferenças na alocação de página de um programa de correr para a próxima liderança para diferenças nos padrões de colisão cache, o que pode levar a grandes diferenças no desempenho do programa. Estas diferenças podem torná-lo muito difícil conseguir um tempo consistente e repetível para uma corrida benchmark.
Para entender o problema, considere uma CPU com 1 MB de cache fisicamente indexada diretamente mapeada de nível 2 e 4 kB páginas de memória virtual. Físico páginas seqüenciais Roteiro para locais sequenciais no cache até depois de 256 páginas o padrão envolve. Nós podemos rotular cada página física com uma cor de 0-255 para indicar onde no cache ele pode ir. Locais dentro de páginas físicas com cores diferentes não podem entrar em conflito no cache.
Um programador de tentar fazer uso máximo do cache pode organizar padrões de acesso de seu programa para que apenas 1 MB de dados precisam ser armazenados em cache em um determinado momento, evitando, assim, acidentes de capacidade. Mas ele também deve garantir que os padrões de acesso não têm erros de conflito. Uma maneira de pensar sobre este problema é dividir as páginas virtuais o programa usa e atribuir-lhes cores virtuais da mesma forma como as cores físicas foram designados para páginas físicas antes. O programador pode então dispor os padrões de acesso do seu código, de modo que não há duas páginas, com a mesma cor em virtual são usados ao mesmo tempo. Existe uma vasta literatura sobre tais optimizações (p.ex. loop de otimização de ninho), em grande parte proveniente do High Performance Computing (HPC) da comunidade.
O problema é que enquanto todas as páginas em uso a qualquer momento podem ter diferentes cores virtuais, alguns podem ter as mesmas cores físicas.Na verdade, se o sistema operacional atribui páginas físicas para páginas virtuais de forma aleatória e uniformemente, é muito provável que algumas páginas terão a mesma cor física e, em seguida locais de essas páginas irão colidir no cache (este é oparadoxo do aniversário).
A solução é ter a tentativa do sistema operacional para atribuir diferentes páginas coloridas física para diferentes cores virtuais, uma técnica chamada para colorir . Embora o mapeamento real do virtual para cor física é irrelevante para o desempenho do sistema, os mapeamentos ímpares são difíceis de acompanhar e tem pouco benefício, de modo mais se aproxima a página para colorir simplesmente tentar manter as cores físicas e virtuais da mesma página.
Se o sistema operacional pode garantir que cada físicas mapas de página para apenas uma cor virtual, então não há aliases virtuais, eo processador pode usar caches praticamente indexados sem necessidade de sondas de alias virtuais extras durante o manuseio perder. Em alternativa, o O / S pode liberar uma página do cache sempre que muda de uma cor virtual para outro. Como mencionado acima, esta abordagem foi utilizada para alguns SPARC precoce e RS / 6000 desenhos.
Hierarquia de cache em um processador moderno
Os processadores modernos possuem múltiplos caches que interagem em chip.
A operação de um cache em particular pode ser completamente especificado por:
- o tamanho do cache
- o tamanho do bloco de cache
- o número de blocos de um conjunto
- a política de substituição do cache
- a política de cache de gravação (write-through ou write-back)
Apesar de todos os blocos de cache em um cache particular, são do mesmo tamanho e tem a mesma associamento, tipicamente caches "de nível inferior" (por exemplo, a cache L1) tem um tamanho menor, tem blocos mais pequenos, e tem menos blocos de um conjunto , enquanto que caches "de alto nível" (como o cache L3) têm maior tamanho, blocos maiores e mais blocos em um conjunto.
Caches especializados
Memória de acesso Pipelined CPUs de vários pontos do gasoduto: busca de instrução, tradução de endereço virtual para físico, e buscar dados (ver oleoduto RISC clássico). O desenho natural é a utilização de diferentes caches físicas para cada um destes pontos, de modo que não um recurso físico tem de ser programado para servir dois pontos no pipeline. Assim, o gasoduto naturalmente acaba com pelo menos três caches separados (instrução, TLB, e dados), cada um especializado para a sua função específica.
Condutas com instrução e dados caches separados, agora predominantes, dizem ter uma arquitetura Harvard. Originalmente, esta frase se refere a máquinas com instruções e dados memórias separadas, que não provaram nada popular. A maioria dos processadores modernos possuem uma única memória arquitetura de von Neumann.
Vítima de cache
Um cache de vítima é um cache usado para armazenar blocos despejadas de um cache da CPU em reposição. O cache vítima encontra-se entre o cache principal e seu caminho de recarga, e apenas detém blocos que foram despejadas do cache principal. O cache vítima geralmente é totalmente associativo, e destina-se a reduzir o número de acidentes de conflito. Muitos programas comumente utilizados não requerem mapeamento associativo para todos os acessos. Na verdade, apenas uma pequena fração dos acessos à memória do programa exigem alta associatividade. O cache vítima explora essa propriedade, oferecendo alta associatividade para apenas estes acessos. Foi introduzido por Norman Jouppi de dezembro de 1990.
Cache de Rastreamento
Um dos exemplos mais extremos de cache de especialização é o cache de vestígios encontrados nas Intel Pentium 4 microprocessadores. Um cache de rastreamento é um mecanismo para aumentar a instrução buscar largura de banda e diminuindo o consumo de energia (no caso do Pentium 4), armazenando os vestígios de instruções que já tenham sido lidas e decodificados.
A mais antiga publicação acadêmica amplamente reconhecido de cache de rastreamento foi porEric Rotenberg,Steve Bennett, eJim Smith em seu papel 1996"Traço de cache:. uma abordagem de baixa latência com a Instrução High Bandwidth Buscando"
Uma publicação anterior é patente US 5381533, "a memória cache de instrução de fluxo dinâmico organizado em torno de segmentos de rastreamento independentes de linha de endereço virtual", deAlex Peleg eUri Weiser da Intel Corp., patente depositado em 30 de março de 1994, uma continuação de um pedido apresentado nos 1992, mais tarde abandonada.
A cache armazena trace instruções ou depois de terem sido decodificada, ou como eles são aposentados. Geralmente, as instruções são adicionadas ao traçar caches em grupos que representam tanto individuais blocos básicos ou vestígios de instrução dinâmicas. Um rastreamento dinâmico ("caminho de rastreamento") contém apenas instruções, cujos resultados são realmente utilizados, e elimina instruções seguintes ramos tomadas (uma vez que eles não são executados); um traço dinâmico pode ser uma concatenação de vários blocos básicos. Isso permite que a instrução unidade de busca de um processador para buscar vários blocos básicos, sem ter que se preocupar com ramificações no fluxo de execução.
Linhas de rastreio são armazenados na memória cache de rastreio baseado na contador de programa da primeira instrução no rastreamento e um conjunto de previsões filial. Isto permite armazenar diferentes caminhos de rastreamento que começam no mesmo endereço, cada um representando os resultados de filiais diferentes. Na busca de instrução fase de um gasoduto, o contador de programa atual, juntamente com um conjunto de previsões filial é verificada no cache de rastreamento para uma batida. Se houver uma batida, uma linha de rastreamento é fornecido para buscar o que não tem que ir para uma cache regular ou a memória para estas instruções. O cache traço continua a alimentar a unidade de busca até que a linha de rastreio termina ou até que haja um misprediction no pipeline. Se existe uma falta, um novo traço começa a ser construído.
Oligo caches também são utilizadas em processadores como oIntel Pentium 4 para armazenar micro-operações já descodificadas, ou tradução de instruções complexas x 86, de modo que a próxima vez que uma instrução for necessário, ele não tem de ser descodificado novamente.
Caches multi-nível
Outra questão é o tradeoff fundamental entre latência de cache e taxa de acerto. Caches maiores têm melhores taxas de sucesso, mas uma latência mais demorada. Para fazer face a essa compensação, muitos computadores usam múltiplos níveis de cache com caches pequenos rápidos apoiados por caches mais lentos maiores.
Caches multi-level geralmente operam, verificando o menor nível 1 (L1) cache do primeiro; se ela atinge, o processador prossegue a alta velocidade. Se o cache menor falha, o próximo cache maior (L2) está marcada, e assim por diante, antes memória externa está marcada.
Como a diferença de latência entre a memória principal ea cache mais rápido tornou-se maior, alguns processadores começaram a utilizar até três níveis de cache no chip. Por exemplo, a Alpha 21164 (1995) tinham de 1 a 64 MB de cache L3 fora do chip; a IBM POWER4 (2001) teve off-chip caches L3 de 32 MB por processador, compartilhados entre vários processadores; o Itanium 2 (2003) teve um 6 MB 3 (L3) de cache on-die nível unificado; o Itanium 2 (2003) MX 2 Módulo incorpora dois processadores Itanium2, juntamente com 64 MB de cache L4 compartilhada em um módulo multi-chip que foi pino compatível com um processador Madison; Da Intel "Tulsa" (2006) codinome produto Xeon MP possui 16 MB de cache on-die L3 compartilhado entre dois núcleos de processador; o AMD Phenom II (2008) tem até 6 MB de cache L3-die unificada; e o Intel Core i7 (2008) tem um 8 MB de cache L3-die unificada que seja inclusiva, compartilhado por todos os núcleos. Os benefícios de um cache L3 depender de padrões de acesso do aplicativo.
Finalmente, no outro extremo da hierarquia de memória, a CPU próprio arquivo registo pode ser considerado o menor, mais rápido de cache no sistema, com a característica especial que é programado em software-normalmente por um compilador, em que atribui registros para segurar valores recuperados da memória principal. (Veja especialmente otimização ninho loop.) Cadastre-se arquivos, por vezes, também têm hierarquia: O Cray-1 (cerca de 1976) tinha 8 endereço "A" e 8 dados escalares registros "S" que eram geralmente utilizável. Houve também um conjunto de 64 endereços "B" e 64 dados escalares "T" registros que levou mais tempo para o acesso, mas foram mais rápidos do que a memória principal. O "B" e registos "T" foram fornecidas porque o Cray-1 não tem um cache de dados. (O Cray-1, no entanto, tem um cache de instrução.)
Chips multi-core
Ao considerar um chip com múltiplos núcleos, há uma questão de saber se os caches deve ser compartilhada ou local para cada núcleo. A implementação de cache compartilhado, sem dúvida, introduz mais fiação e complexidade. Mas, então, tem um cache por chip de , em vez de núcleo , reduz grandemente a quantidade de espaço necessário e, portanto, pode-se incluir um cache maior. Normalmente verifica-se que a partilha de cache L1 é indesejável uma vez que o aumento da latência é tal que cada núcleo será executado consideravelmente mais lento do que um chip single-core. Mas, em seguida, para o nível mais alto (a última chamada antes de acessar memória), ter um cache global é desejável por várias razões. Por exemplo, um chip de oito núcleos com três níveis pode incluir um cache L1 para cada núcleo, um cache L3 compartilhado por todos os núcleos, com a cache L2 intermediário, por exemplo, um para cada par de núcleos.
Separe contra unificada
Em uma estrutura de cache separado, instruções e dados são armazenados em cache em separado, o que significa que uma linha de cache é usado para armazenar em cache tanto instruções ou dados, mas não ambos. Em um unificada, essa restrição é removida.
Exclusive contra inclusiva
Caches multi-level introduzir novas decisões de design. Por exemplo, em alguns processadores, todos os dados no cache L1 também deve estar em algum lugar no cache L2. Estes são chamados caches estritamente inclusivo . Outros processadores (como o AMD Athlon) têm exclusivos caches - dados está garantido para estar em no máximo um dos caches L1 e L2, nunca em ambos. Ainda outros processadores (como o Intel Pentium II, III, e 4), não exigem que os dados no cache L1 também residir no cache L2, embora possa fazê-lo muitas vezes. Não há nenhum nome universalmente aceito para esta política intermediário.
A vantagem de caches exclusivos é que eles armazenam mais dados. Esta vantagem é maior quando o cache L1 exclusivo é comparável com o cache L2, e diminui se o cache L2 é muitas vezes maior do que o cache L1. Quando os acidentes L1 e L2 bate em um acesso, a linha de cache bater na L2 é trocada com uma linha no L1. Esta troca é um pouco mais trabalho do que apenas copiar uma linha de L2 a L1, que é o que um cache inclusive faz.
Uma vantagem de caches estritamente inclusivas é que quando dispositivos externos ou outros processadores em um sistema multiprocessador deseja remover uma linha de cache do processador, eles precisam ter apenas o processador de verificar o cache L2. Em hierarquias de cache que não apliquem a inclusão, o cache L1 deve ser verificado também. Como desvantagem, existe uma correlação entre os valores associativos de caches L1 e L2: se a cache L2 não tem pelo menos tantas formas como L1 armazena todos juntos, o associamento eficaz dos caches L1 é restrito. Outra desvantagem do esconderijo inclusiva é que sempre que houver um despejo em cache L2, as linhas (possivelmente) correspondentes em L1 também tem que se despejada a fim de manter inclusão. Isto é bastante um trabalho pouco, e resultaria em uma maior taxa de erro L1.
Outra vantagem de caches inclusivas é que o cache maior possível utilizar linhas de cache maiores, o que reduz o tamanho das etiquetas cache secundário. (Caches Exclusivo exigem ambos os caches de ter as mesmas linhas de cache tamanho, de modo que as linhas de cache pode ser trocado em uma miss L1, L2 hit). Se o cache secundário é uma ordem de grandeza maior do que o primário, e os dados de memória cache é uma ordem de magnitude maior do que as marcas de cache, esta área da marca economizado pode ser comparável à área adicionais necessários para armazenar os dados na cache L1 L2 .
Exemplo: o K8
Para ilustrar tanto especialização e multi-level caching, aqui é a hierarquia de cache do núcleo K8 no AMDAthlon 64 CPU.
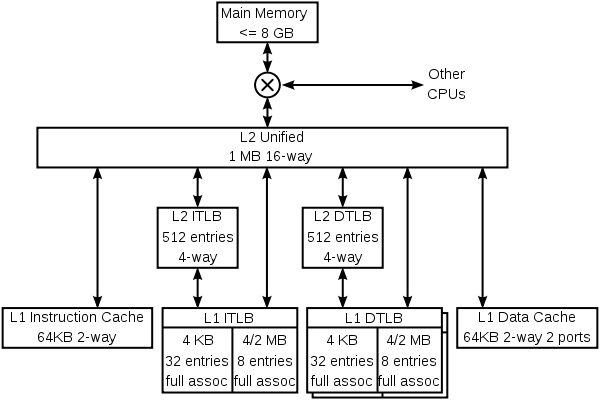
O K8 tem quatro caches especializados: um cache de instrução, uma instrução TLB, uma dados TLB, e um cache de dados. Cada um desses caches é especializado:
- O K8 também armazena em cache informações que nunca é armazenado em informações de previsão de memória. Esses caches não são mostradas no diagrama acima. Como é habitual para esta classe de CPU, o K8 tem bastante complexo previsão de desvios, com tabelas que ajudam a prever se as ramificações são tomadas e outras tabelas que prevêem os alvos dos ramos e saltos. Algumas dessas informações está associada com as instruções, tanto no cache de instrução de nível 1 e do cache secundário unificado.
O K8 usa um truque interessante para armazenar informações de previsão com instruções no cache secundário. As linhas no cache secundário estão protegidos contra a corrupção de dados acidental (por exemplo, uma greve partícula alfa) por qualquer ECC ou paridade, dependendo se essas linhas foram despejados de dados ou caches instrução primária. Uma vez que o código de paridade leva menos bits do que o código ECC, linhas do cache de instrução tem alguns bits de reserva. Estes bits são usados para armazenar em cache as informações de previsão de desvio associado com essas instruções. O resultado líquido é que o preditor ramo tem um maior tabela história eficaz, e por isso tem uma melhor precisão.
Mais hierarquias
Outros processadores têm outros tipos de preditores (por exemplo, o preditor loja-a-carga extracorpórea no Dezembro Alpha 21264), e vários preditores especializados possam florescer em futuros processadores.
Esses preditores são caches em que eles armazenam informações que é caro para computar. Parte da terminologia usada quando se discute preditores é o mesmo que para caches (fala-se de um hit em um preditor ramo), mas preditores não são geralmente consideradas como parte da hierarquia de cache.
O K8 mantém as instruções e dados caches coerentes em hardware, o que significa que uma loja em uma instrução a seguir de perto a instrução loja vai mudar isso seguindo as instruções. Outros processadores, como os da família Alpha e MIPS, têm contado com software para manter o cache de instrução coerente. Lojas não são garantidos para aparecer no fluxo de instrução até que um programa chama uma instalação de sistema operacional para assegurar a coerência.
Implementação
Cache lê o funcionamento da CPU são mais comum que leva mais do que um único ciclo. Tempo de execução do programa tende a ser muito sensível à latência de um acerto de cache de dados de nível 1. Uma grande quantidade de esforço de design, e muitas vezes a área de alimentação e silício são gastos fazendo os caches o mais rápido possível.
O cache mais simples é um cache diretamente mapeada praticamente indexado. O endereço virtual é calculado com um somador, a porção relevante do endereço extraída e utilizada para indexar uma SRAM, que retorna os dados carregados. O byte de dados é alinhado de um deslocador de byte, e a partir daí é desviado para a próxima operação. Não há necessidade de qualquer tag check-in do circuito interno - na verdade, as marcas precisam nem mesmo ser lido. Mais tarde na calha, mas antes a instrução de carga é aposentado, o tag para os dados carregados devem ser lidas, e ao confronto com o endereço virtual para garantir que não foi um sucesso cache. Em uma falta, o cache é atualizado com a linha de cache solicitado eo gasoduto é reiniciado.
Um cache associativa é mais complicado, porque de alguma forma de tag deve ser lido para determinar qual entrada do cache para selecionar. Um N-way set-associativa nível 1 de cache normalmente lê todas as possíveis marcas N e dados N em paralelo, e em seguida, escolhe os dados associados com a tag correspondente. Caches de nível 2, por vezes, poupar energia através da leitura das etiquetas em primeiro lugar, de modo que apenas um elemento dados são lidos a partir da SRAM de dados.

O diagrama da direita destina-se a clarificar a forma como os vários campos de endereço são utilizadas. Bit endereço 31 é mais significativo, bit 0 é menos significativo. O diagrama mostra a SRAM, indexação e multiplexação para um 4 kB, 2-way set-associativa, praticamente indexados eo cache praticamente marcado com 64 linhas B, um 32b e 32b ler largura endereço virtual.
Como o cache é de 4 kB e tem 64 linhas B, existem apenas 64 linhas no cache, e nós ler dois ao mesmo tempo a partir de uma SRAM Tag, que tem 32 linhas, cada uma com um par de 21 marcas bits. Embora qualquer função de endereço virtual bits de 31 a 6 pode ser utilizado para indexar o tag e SRAM de dados, é mais simples de usar os bits menos significativos.
Da mesma forma, porque o cache é de 4 kB e tem um caminho de leitura 4 B, e lê dois caminhos para cada acesso, a SRAM de dados é de 512 linhas por 8 bytes de largura.
Um cache de mais moderno pode ser 16 kB, 4-way set-associativa, praticamente indexado, praticamente deu a entender, e fisicamente marcado, com 32 linhas B, 32b ler endereços físicos de largura e 36b. A recorrência caminho ler para tal esconderijo é muito parecido com o caminho acima. Em vez de etiquetas, vhints são lidos, e comparados com um subconjunto do endereço virtual. Mais tarde no pipeline, o endereço virtual é traduzido em um endereço físico pela TLB, ea tag físico é lido (apenas um, como os suprimentos qual a forma de cache para ler vhint). Finalmente, o endereço físico é comparada com a tag físico para determinar se houve um acerto.
Alguns projetos SPARC têm melhorado a velocidade de seus caches L1 por um portão de alguns atrasos por colapso a víbora endereço virtual para os descodificadores SRAM. Ver Sum dirigida descodificador.
História
O início da história da tecnologia de cache está intimamente ligada com a invenção e uso de memória virtual. Devido à escassez e custo dos semi-condutores, memórias, computadores de grande porte início da década de 1960 usada uma hierarquia complexa de memória física, mapeado sobre um espaço de memória virtual usada plana por programas. As tecnologias de memória que abrangem semi-condutores, magnetic core, tambor e disco. A memória virtual visto e utilizado pelos programas seria plana e cache seria usado para obter dados e instruções para a memória de acesso mais rápido à frente do processador. Amplos estudos foram feitos para otimizar os tamanhos de cache. Valores ótimos foram encontrados para depender muito da linguagem de programação usada com Algol precisar o menor e Fortran e Cobol necessitando maiores tamanhos de cache.
Nos primeiros dias da tecnologia de microcomputador, acesso à memória foi apenas um pouco mais lento do que registrar o acesso. Mas desde os anos 1980 a diferença de desempenho entre o processador ea memória tem sido crescente. Microprocessadores ter avançado muito mais rápido do que a memória, especialmente em termos de sua operação de frequência, de modo a memória tornou-se um desempenho gargalo. Embora fosse tecnicamente possível ter toda a memória principal tão rápido quanto o CPU, um caminho mais viável economicamente foi tomada: usar muita memória de baixa velocidade, mas também introduzir uma pequena memória cache de alta velocidade para aliviar a lacuna de desempenho. Isto proporcionou uma ordem de magnitude mais capacidade de para o mesmo preço, com apenas uma performance combinada ligeiramente reduzida.
Primeiras implementações TLB
Os primeiros usos documentados de uma TLB estavam no GE 645 e aIBM 360/67, ambas as quais usado como uma memória associativa uma TLB.
Cache de dados primeiro
O primeiro uso documentado de um cache de dados foi naIBMSystem / 360 Modelo 85.
Em processadores x86
Como o microprocessadores x86 atingiu taxas de clock de 20 MHz e acima no 386, de pequenas quantidades de memória cache rápido começaram a ser destaque em sistemas para melhorar o desempenho. Isso aconteceu porque o DRAM usada para a memória principal tinha latência significativa, até 120 ns, bem como os ciclos de atualização. O cache foi construída a partir de mais caro, mas significativamente mais rápido, SRAM, que no momento em que teve latências de cerca de 10 ns. Os primeiros caches foram externo para o processador e, normalmente localizado na placa-mãe em forma de oito ou nove dispositivos DIP colocados em soquetes para permitir o cache como um extra opcional ou atualizar recurso.
Algumas versões do processador Intel 386 poderia apoiar 16-64KB de cache externo.
Com o Processador 486, um cache de 8 kB foi integrado diretamente no CPU die. Esta cache foi denominado Nível 1 ou cache L1 para diferenciá-lo do mais lento on-placa-mãe, ou Nível 2 (L2) cache. Esses caches on-motherboard eram muito maiores, com o tamanho mais comum é de 256 kB. A popularidade de cache no motherboard continuou através da era Pentium MMX, mas foi tornada obsoleta pela introdução de SDRAM ea crescente disparidade entre taxas de clock de ônibus e taxas de clock da CPU, o que causou o cache on-placa-mãe para ser apenas ligeiramente mais rápido do que a memória principal .
O próximo desenvolvimento na implementação de cache nos microprocessadores x86 começou com oPentium Pro, que trouxe o cache secundário para o mesmo pacote que o microprocessador, com clock de a mesma frequência que o microprocessador.
On-mãe caches gostei popularidade graças prolongada ao AMD K6-2 e processadores AMD K6-III que ainda utilizados o venerável soquete 7, que foi usado anteriormente pela Intel com caches on-motherboard. K6-III incluiu 256 kb on-die cache L2 e aproveitou o cache on-board como um terceiro cache de nível, chamado L3 (placas-mãe com até 2 MB de cache on-board foram produzidos). Após o Socket-7 tornou-se obsoleto, esconderijo on-motherboard desapareceu dos sistemas x86.
O cache de três níveis foi usado novamente em primeiro lugar com a introdução de vários núcleos de processador, em que o L3 foi adicionado à CPU matriz. Tornou-se comum ter os três níveis ser maior em tamanho do que o outro e hoje não é raro encontrar Nível 3 tamanhos de cache de oito megabytes. Esta tendência parece continuar no futuro previsível.
A pesquisa atual
Os primeiros desenhos de cache voltados inteiramente para o custo direto de cache e memória RAM e velocidade de execução média. Mais projetos recentes de cache também considerar a eficiência energética, a tolerância a falhas, e outras metas.
Existem várias ferramentas disponíveis para arquitetos de computador para ajudar a explorar compensações entre ciclo de cache de tempo, energia e área. Essas ferramentas incluem o código-fonte aberto simulador de cache de cactos e de código aberto conjunto simulador de instrução SimpleScalar.
Cache de Multi-portado
Um cache multi-portado é um cache que pode servir mais de um pedido por vez. Ao acessar um cache tradicional que normalmente utilizar um único endereço de memória, enquanto que em um cache multi-portado poderemos solicitar endereços N de cada vez - onde N é o número de portas que conectados através do processador eo cache. O benefício disso é que um processador em conduta pode acessar a memória de diferentes fases em seu pipeline. Outra vantagem é que ele permite que o conceito de processadores super escalares através de diferentes níveis de cache.